3.2. pandas 1#
pandasはリッチなデータ構造と関数を提供します。DataFrameと呼ばれる二次元の表形式で分析を容易にします。そのほか、リレーショナルデータベース(SQLなど)の柔軟なデータ操作能力を持ち合わせます。 もともと金融データ分析アプリケーションとしてのツールとして設計されたこともあり、時系列データも扱いやすいです。
3.2.1. pandasの基本的な使い方#
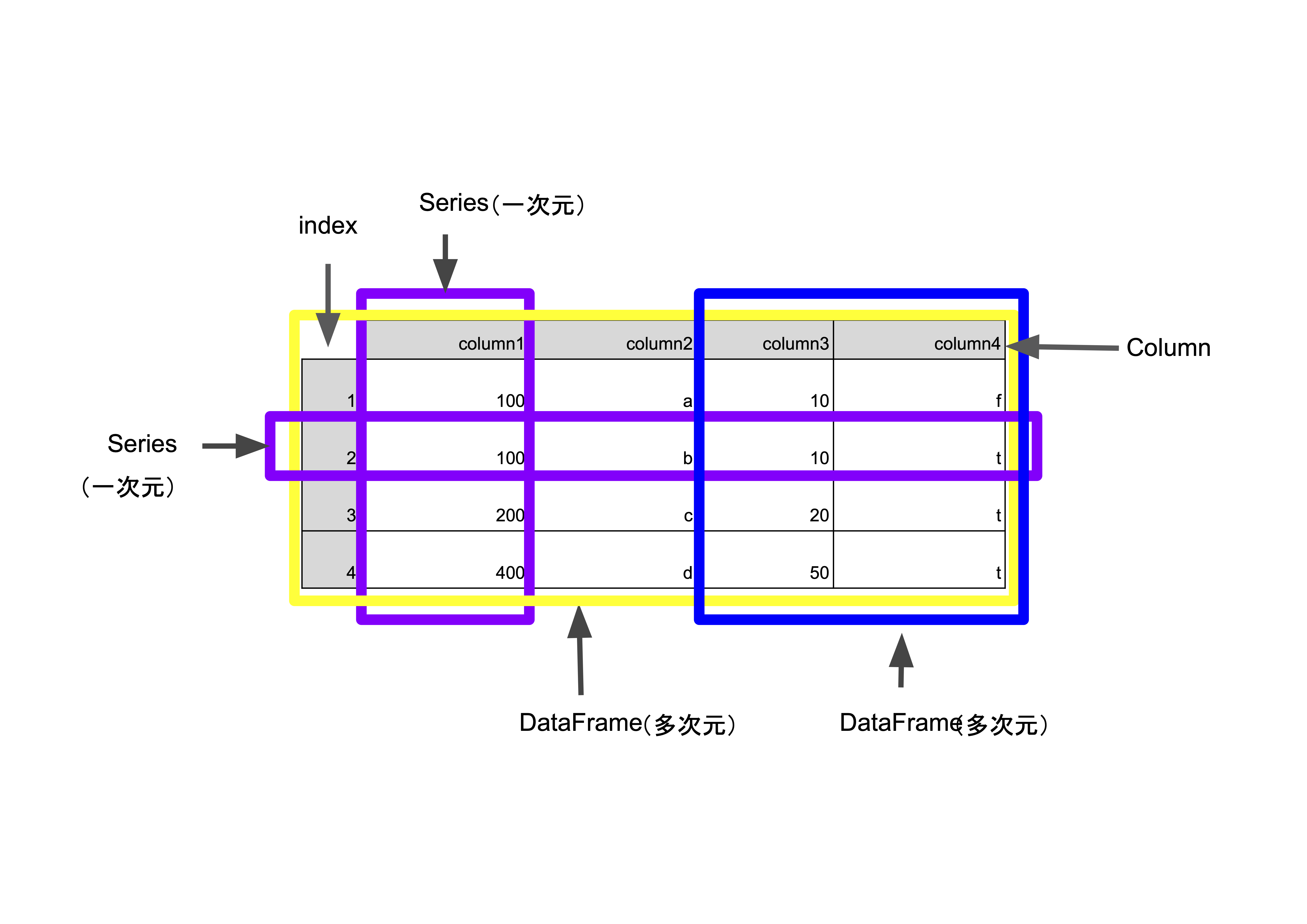
DataFrame : 多次元、行と列がある。(いわゆる表形式)
Series : 1次元。一つの行もしくは列のみ。
import pandas as pd #pandasはpdとしてimportすることが慣例となっています。
import numpy as np
テーブルデータをつくってみましょう。
まずは、1列ずつデータをpd.Seriesで作ります。
price = pd.Series([100, 40, 300, np.nan , 500, 1000, 300, 400, 240, 3000])
print(price)
0 100.0
1 40.0
2 300.0
3 NaN
4 500.0
5 1000.0
6 300.0
7 400.0
8 240.0
9 3000.0
dtype: float64
num = pd.Series([5, 2, 1, 0, 4, 200, 7, 19, 20, 100])
datetimes = pd.date_range('20180601', periods=10, freq= '627H')
print(datetimes)
DatetimeIndex(['2018-06-01 00:00:00', '2018-06-27 03:00:00',
'2018-07-23 06:00:00', '2018-08-18 09:00:00',
'2018-09-13 12:00:00', '2018-10-09 15:00:00',
'2018-11-04 18:00:00', '2018-11-30 21:00:00',
'2018-12-27 00:00:00', '2019-01-22 03:00:00'],
dtype='datetime64[ns]', freq='627H')
列データを組み合わせてデータフレームを作ります
df = pd.DataFrame({'price':price, 'num': num, 'datetime': datetimes })
df
| price | num | datetime | |
|---|---|---|---|
| 0 | 100.0 | 5 | 2018-06-01 00:00:00 |
| 1 | 40.0 | 2 | 2018-06-27 03:00:00 |
| 2 | 300.0 | 1 | 2018-07-23 06:00:00 |
| 3 | NaN | 0 | 2018-08-18 09:00:00 |
| 4 | 500.0 | 4 | 2018-09-13 12:00:00 |
| 5 | 1000.0 | 200 | 2018-10-09 15:00:00 |
| 6 | 300.0 | 7 | 2018-11-04 18:00:00 |
| 7 | 400.0 | 19 | 2018-11-30 21:00:00 |
| 8 | 240.0 | 20 | 2018-12-27 00:00:00 |
| 9 | 3000.0 | 100 | 2019-01-22 03:00:00 |
上のやり方のように1列ずつ作ってもOKですが、次のcellのようにまとめて作ることもできます。
df = pd.DataFrame({'price':[100, 40, 300, np.nan , 500, 1000, 300, 400, 240, 3000],
'num': [5, 2, 1, 0, 4, 200, 7, 19, 20, 100],
'datetime': pd.date_range('20180601', periods=10, freq= '627H') })
df
| price | num | datetime | |
|---|---|---|---|
| 0 | 100.0 | 5 | 2018-06-01 00:00:00 |
| 1 | 40.0 | 2 | 2018-06-27 03:00:00 |
| 2 | 300.0 | 1 | 2018-07-23 06:00:00 |
| 3 | NaN | 0 | 2018-08-18 09:00:00 |
| 4 | 500.0 | 4 | 2018-09-13 12:00:00 |
| 5 | 1000.0 | 200 | 2018-10-09 15:00:00 |
| 6 | 300.0 | 7 | 2018-11-04 18:00:00 |
| 7 | 400.0 | 19 | 2018-11-30 21:00:00 |
| 8 | 240.0 | 20 | 2018-12-27 00:00:00 |
| 9 | 3000.0 | 100 | 2019-01-22 03:00:00 |
dfのタイプを確認します。
type(df)
pandas.core.frame.DataFrame
price列の型も確認してみましょう
type(df['price'])
pandas.core.series.Series
2つ以上の列(もしくは行)を選択するとSeriesではなくDataFrameとなります。
type(df[['price','num']])
pandas.core.frame.DataFrame
1つの行もSeriesです。
df.iloc[0]
price 100.0
num 5
datetime 2018-06-01 00:00:00
Name: 0, dtype: object
type(df.iloc[0])
pandas.core.series.Series
dtypesで列ごとのタイプを一括して確認できます
df.dtypes
price float64
num int64
datetime datetime64[ns]
dtype: object
headで行数を指定することで、DataFrameの最初の3行を表示できます
df.head(3)
| price | num | datetime | |
|---|---|---|---|
| 0 | 100.0 | 5 | 2018-06-01 00:00:00 |
| 1 | 40.0 | 2 | 2018-06-27 03:00:00 |
| 2 | 300.0 | 1 | 2018-07-23 06:00:00 |
DataFrameのランダムな3行を表示するにはsampleを用います
df.sample(3)
| price | num | datetime | |
|---|---|---|---|
| 8 | 240.0 | 20 | 2018-12-27 00:00:00 |
| 7 | 400.0 | 19 | 2018-11-30 21:00:00 |
| 9 | 3000.0 | 100 | 2019-01-22 03:00:00 |
DataFrameの最後の3行をtailを用いて表示できます
df.tail(3)
| price | num | datetime | |
|---|---|---|---|
| 7 | 400.0 | 19 | 2018-11-30 21:00:00 |
| 8 | 240.0 | 20 | 2018-12-27 00:00:00 |
| 9 | 3000.0 | 100 | 2019-01-22 03:00:00 |
DataFrameのIndexを確認します
df.index
RangeIndex(start=0, stop=10, step=1)
DataFrameのcolumnsを確認します
df.columns
Index(['price', 'num', 'datetime'], dtype='object')
列の抽出は次のように列名を指定することできます
df['price']
0 100.0
1 40.0
2 300.0
3 NaN
4 500.0
5 1000.0
6 300.0
7 400.0
8 240.0
9 3000.0
Name: price, dtype: float64
複数列の抽出の抽出もできます
df[['price','datetime']]
| price | datetime | |
|---|---|---|
| 0 | 100.0 | 2018-06-01 00:00:00 |
| 1 | 40.0 | 2018-06-27 03:00:00 |
| 2 | 300.0 | 2018-07-23 06:00:00 |
| 3 | NaN | 2018-08-18 09:00:00 |
| 4 | 500.0 | 2018-09-13 12:00:00 |
| 5 | 1000.0 | 2018-10-09 15:00:00 |
| 6 | 300.0 | 2018-11-04 18:00:00 |
| 7 | 400.0 | 2018-11-30 21:00:00 |
| 8 | 240.0 | 2018-12-27 00:00:00 |
| 9 | 3000.0 | 2019-01-22 03:00:00 |
特定の列をindexにすることもできます
df = df.set_index(['datetime'])
df
| price | num | |
|---|---|---|
| datetime | ||
| 2018-06-01 00:00:00 | 100.0 | 5 |
| 2018-06-27 03:00:00 | 40.0 | 2 |
| 2018-07-23 06:00:00 | 300.0 | 1 |
| 2018-08-18 09:00:00 | NaN | 0 |
| 2018-09-13 12:00:00 | 500.0 | 4 |
| 2018-10-09 15:00:00 | 1000.0 | 200 |
| 2018-11-04 18:00:00 | 300.0 | 7 |
| 2018-11-30 21:00:00 | 400.0 | 19 |
| 2018-12-27 00:00:00 | 240.0 | 20 |
| 2019-01-22 03:00:00 | 3000.0 | 100 |
print(df.index[0]) # indexの0番目の値を確認
print(df.index[-1]) # indexの末尾の値を確認
2018-06-01 00:00:00
2019-01-22 03:00:00
indexをresetして0から振り直すにはreset_indexが使えます。
df = df.reset_index()
df.head(2)
| datetime | price | num | |
|---|---|---|---|
| 0 | 2018-06-01 00:00:00 | 100.0 | 5 |
| 1 | 2018-06-27 03:00:00 | 40.0 | 2 |
indexには複数の列を指定することも可能です。(Multiindex)
df = df.set_index(['datetime','num'])
df
| price | ||
|---|---|---|
| datetime | num | |
| 2018-06-01 00:00:00 | 5 | 100.0 |
| 2018-06-27 03:00:00 | 2 | 40.0 |
| 2018-07-23 06:00:00 | 1 | 300.0 |
| 2018-08-18 09:00:00 | 0 | NaN |
| 2018-09-13 12:00:00 | 4 | 500.0 |
| 2018-10-09 15:00:00 | 200 | 1000.0 |
| 2018-11-04 18:00:00 | 7 | 300.0 |
| 2018-11-30 21:00:00 | 19 | 400.0 |
| 2018-12-27 00:00:00 | 20 | 240.0 |
| 2019-01-22 03:00:00 | 100 | 3000.0 |
# indexをresetするには`reset_index`を使います。
df = df.reset_index()
df
| datetime | num | price | |
|---|---|---|---|
| 0 | 2018-06-01 00:00:00 | 5 | 100.0 |
| 1 | 2018-06-27 03:00:00 | 2 | 40.0 |
| 2 | 2018-07-23 06:00:00 | 1 | 300.0 |
| 3 | 2018-08-18 09:00:00 | 0 | NaN |
| 4 | 2018-09-13 12:00:00 | 4 | 500.0 |
| 5 | 2018-10-09 15:00:00 | 200 | 1000.0 |
| 6 | 2018-11-04 18:00:00 | 7 | 300.0 |
| 7 | 2018-11-30 21:00:00 | 19 | 400.0 |
| 8 | 2018-12-27 00:00:00 | 20 | 240.0 |
| 9 | 2019-01-22 03:00:00 | 100 | 3000.0 |