3.4. ファイルの読み書き#
3.4.1. 絶対パスと相対パス#
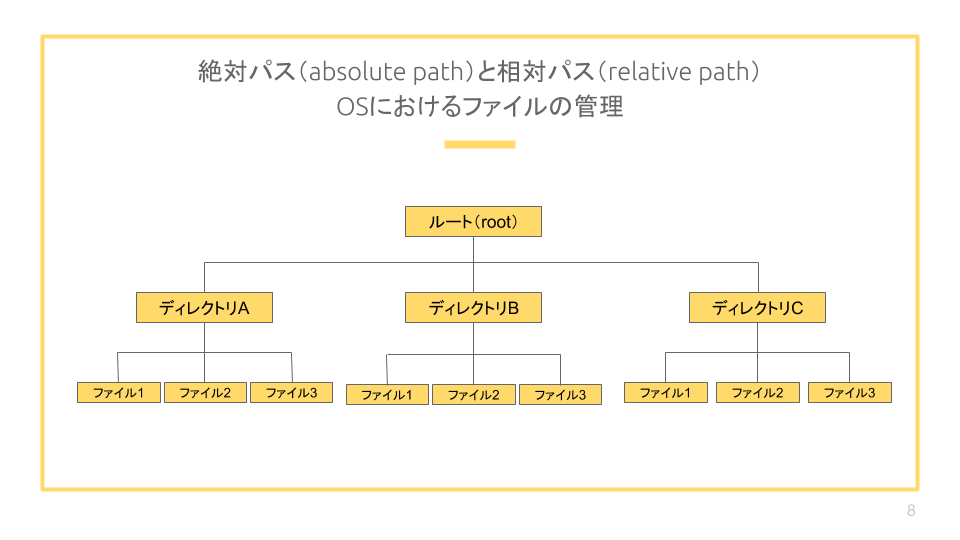
一般的なファイル構造
Mac/Linuxの場合
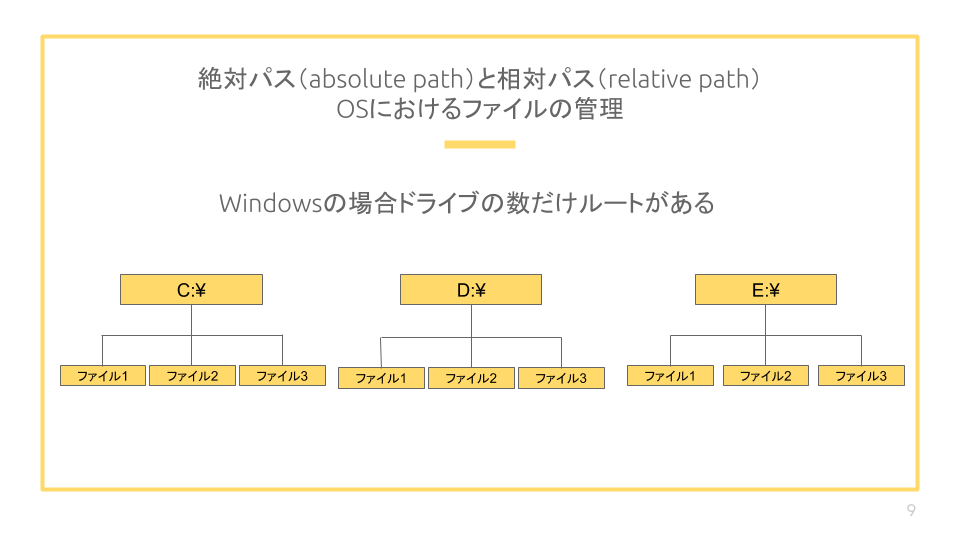
Winodowsの場合
3.4.1.1. 絶対パス(absolute path)#
ルートからの道順(パス)を指定する方法
厳密なルートで間違いが少ない
長くなりがち
Windowsの例
C:¥Users¥username¥Desktop¥Folder1¥test.txt
Mac/Linuxの例
/Users/username/folder1/test.txt
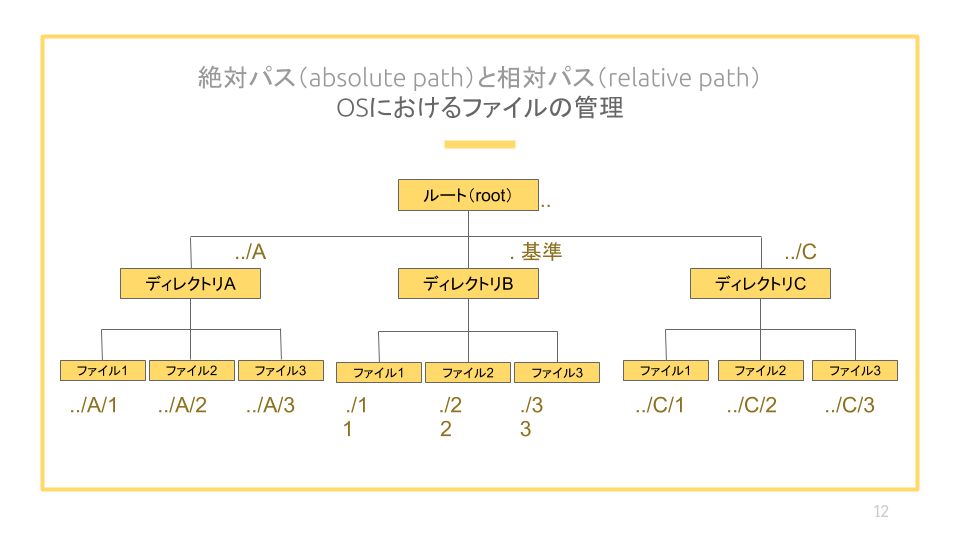
3.4.1.2. 相対パス(relative path)#
基準となるディレクトリ(カレントディレクトリ)からの道順(パス)を指定する方法
.. で1階層上のディレクトリ、.で同じディレクトリ
現在の場所(カレントディレクトリ)は、%pwdで確認できます。
%pwd
'/Users/yuyashibu/Library/CloudStorage/GoogleDrive-yysby@g.ecc.u-tokyo.ac.jp/My Drive/class/iii社会情報学研究法IV/iiimethodsiv/docs/sec03'
現在の場所(カレントディレクトリ)にあるファイルをリストアップするためには%lsで確認できます。
%ls
exercise.ipynb option_text_viz.ipynb test.pkl
index.md pandas1.ipynb testcsv.csv
matplotlib.ipynb pandas2.ipynb text_ja.csv
new_list.pkl pandas_datetime.ipynb
numpy.ipynb read_write.ipynb
3.4.2. pandasを用いたcsvの読み書き#
import numpy as np
import pandas as pd
price = [100, 40, 300, np.nan , 500, 1000, 300, 400, 240, 3000]
num = [5, 2, 1, 0, 4, 200, 7, 19, 20, 100]
datetimes = pd.date_range('20180601', periods=10, freq= '627H')
df = pd.DataFrame({'price':price, 'num': num, 'datetime': datetimes })
df
| price | num | datetime | |
|---|---|---|---|
| 0 | 100.0 | 5 | 2018-06-01 00:00:00 |
| 1 | 40.0 | 2 | 2018-06-27 03:00:00 |
| 2 | 300.0 | 1 | 2018-07-23 06:00:00 |
| 3 | NaN | 0 | 2018-08-18 09:00:00 |
| 4 | 500.0 | 4 | 2018-09-13 12:00:00 |
| 5 | 1000.0 | 200 | 2018-10-09 15:00:00 |
| 6 | 300.0 | 7 | 2018-11-04 18:00:00 |
| 7 | 400.0 | 19 | 2018-11-30 21:00:00 |
| 8 | 240.0 | 20 | 2018-12-27 00:00:00 |
| 9 | 3000.0 | 100 | 2019-01-22 03:00:00 |
df.to_csv('./testcsv.csv')
ちゃんと保存されているか、確認してみましょう。
%ls
exercise.ipynb option_text_viz.ipynb test.pkl
index.md pandas1.ipynb testcsv.csv
matplotlib.ipynb pandas2.ipynb text_ja.csv
new_list.pkl pandas_datetime.ipynb
numpy.ipynb read_write.ipynb
3.4.2.1. pandasを用いたcsvの読み込み#
保存したcsvファイルをDataFrameとして読み込む
r_df = pd.read_csv('testcsv.csv', index_col = 0)
r_df
| price | num | datetime | |
|---|---|---|---|
| 0 | 100.0 | 5 | 2018-06-01 00:00:00 |
| 1 | 40.0 | 2 | 2018-06-27 03:00:00 |
| 2 | 300.0 | 1 | 2018-07-23 06:00:00 |
| 3 | NaN | 0 | 2018-08-18 09:00:00 |
| 4 | 500.0 | 4 | 2018-09-13 12:00:00 |
| 5 | 1000.0 | 200 | 2018-10-09 15:00:00 |
| 6 | 300.0 | 7 | 2018-11-04 18:00:00 |
| 7 | 400.0 | 19 | 2018-11-30 21:00:00 |
| 8 | 240.0 | 20 | 2018-12-27 00:00:00 |
| 9 | 3000.0 | 100 | 2019-01-22 03:00:00 |
3.4.2.2. 参考 pandasを用いた様々なファイル形式の読み書き#
pandasを用いたcsvの読み書きは以前紹介しましたが、その他の形式のファイルの読み書きもpandasでは行えます。
いくつか代表的なものを紹介します。
read_csv: 区切り文字で区切られたデータを読み込む
read_excel: ExcelのXLSやXLSXファイルからデータを読み込む
read_json: JSON(JavaScript Object Notation)の文字列表現からデータを読み込む
read_pickle: Pythonのpickleバイナリ形式で書き出されたオブジェクトを読み込む
r_df = pd.read_csv('testcsv.csv', index_col = 0)
r_df.info()
<class 'pandas.core.frame.DataFrame'>
Index: 10 entries, 0 to 9
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 price 9 non-null float64
1 num 10 non-null int64
2 datetime 10 non-null object
dtypes: float64(1), int64(1), object(1)
memory usage: 320.0+ bytes
r_df.to_pickle('./test.pkl')
r_df_pkl = pd.read_pickle('./test.pkl')
r_df_pkl.info()
<class 'pandas.core.frame.DataFrame'>
Index: 10 entries, 0 to 9
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 price 9 non-null float64
1 num 10 non-null int64
2 datetime 10 non-null object
dtypes: float64(1), int64(1), object(1)
memory usage: 320.0+ bytes
3.4.3. pickleの読み書き#
import pickle
new_list = [1, 2, 3, 4, 5, 10, 12, 4, 14]
with open('./new_list.pkl','wb') as f:
pickle.dump(new_list, f)
with open('./new_list.pkl','rb') as f:
new_list_2 = pickle.load(f)
type(new_list_2)
list
new_list_2
[1, 2, 3, 4, 5, 10, 12, 4, 14]